データベーススペシャリストを2週間で合格できませんでした
はじめに
データベーススペシャリストはIPAの試験でありは高度試験レベル4に分類され、
合格率は17%前後の試験です。
H29,4/17に受験しましたが、
手応え的に不合格です(午後IIの試験中1時間ぐらいは瞑想していました)。
「人生でDBとか触ったことないし、業務でも使わないし、子供生まれたばかりで全然勉強できなかった」
と自分の中で言い訳して「しょうがない」で片付けてしまっては成長できないので
今回の失敗を自分用のメモとして振り返ります。
データベースと私
そもそもですがデータベースに興味があるかと聞かれるとゼロです。
上に書いた通り業務でも使いませんし、人生で触ったこともありません。
ただ、自分がやりたいことを実現するために必要な要素の一つだったので勉強&受験してみました。
振り返り
大きく4つの観点から振り返ります。
①うまくいった視点レベルでの改善
②うまくいった行動レベルでの改善
③失敗した視点レベルでの改善
④失敗した行動レベルでの改善
上記の振り返り方法は
梅原大吾著書の「1日ひとつだけ、強くなる」の内容を参考にしてみました。
この本は世界1位を何回も取り続けている人はどのような考え方で行動しているのか気になって読みました。

1日ひとつだけ、強くなる。 世界一プロ・ゲーマーの勝ち続ける64の流儀
- 作者: 梅原大吾
- 出版社/メーカー: KADOKAWA/中経出版
- 発売日: 2015/07/10
- メディア: 単行本
- この商品を含むブログ (6件) を見る
①うまくいった視点レベルでの改善
ここでは考え方として良かった部分と改善を考える。
- 通勤時間の4時間/日は午前Ⅱ対策にする
→あまり座れず乗り換えもあるので、簡単にできる午前Ⅱの勉強に充てる
→午前Ⅱは2週間で過去問9割ほど正解できるレベルになった。
→平日は仕事と育児で午前対策しかできなかった。
→午後問を朝一問やるなどの対策が必要だった。 - 午後問の勉強範囲を限定する
→選択問題で「概念データベース」を中心に勉強する。
→物理設計はやらないことで、午後Ⅰ・Ⅱの勉強範囲を一緒にする。 - 勉強の順番を午前Ⅱ→午後Ⅰ・Ⅱ→午前Ⅱにする
→初めに午前Ⅱを行うことでDBSの単語を覚えて学習スピードを上げる。 - 最後までやる
→試験4日前時点で「間に合わない100%不合格だろう」と感じていたが試験直前まで勉強した。
→試験直前まで勉強していると勉強時間以外に自分に足りなかった要素が課題となって見えてきた。
→自分の現状の実力を把握できた。頑張れば本当はできるという甘い考えは排除できた。
→脳に負荷をかけることで勉強中別のアイデアがたくさん出てくることに気づいた。いつもと違うことをやっている方が違うアイデアが出てくる。
②うまくいった行動レベルでの改善
ここでは考え方は正しいし、実際考えどおりにできたことをさらに改善する。
- 勉強のための徹夜は絶対にしない。(これは大学生のときに何度も検証して失敗してきた)
→徹夜しなくてはいけないような勉強スケジュールに問題があった - 午後Ⅱを最後まで受ける
→わからないなりになんとか解答欄を埋めて最後まで粘ってみた。
→自分の限界と問題との距離感を感じた。
③失敗した視点レベルでの改善
ここでは考え方がそもそも間違っていたことの改善
- 情報処理安全確保支援士(セキュリティスペシャリスト)と同じ勉強法でいけると思っていた。
→セスペの午後Ⅱは午後Ⅰの問題の延長なので、午後Ⅰをしっかりと勉強していれば午後Ⅱの対策は不要だった。
→DBSは午後ⅠとⅡで求められているものが変わり、午後Ⅱの対策(トップダウンアプローチの解法など)をしっかりとしないといけなかった。
④失敗した行動レベルでの改善
ここでは間違えた行動を振り返る
- 参考書を間違える
→試験の対策で参考書選びは非常に大事である。これについては以下過去記事にも記載した。
→セスペのときに購入した参考書が非常に良かったので、DBSについても同じ出版社の参考書を買ったがこれが大きな間違いだった。
→4000円弱かけて買った参考書は初学者には非常に難しく全然読めなかった。
→このままではまずいと別途参考書を購入したが、すでに試験6日前だったので学習が間に合わなかった。 - 参考書へのペン入れ
→最終的に売ることを考えて問題などに対してペン入れしていなかった。
→このため問題を印刷したり頭の中で考えたりノートに写したりと無駄が多かった。
→残り3日前に諦めてペン入れをした。来年も使えるようにFrixionで書き込んだ。書き込んだ文字は本ごと温めれば消せるはず。 - 会社の昼休みに勉強する
→休憩時間はしっかりと休まないとパフォーマンスが出ないが、そんなことを言っていられないぐらい勉強不足だった - 集中力の低下 →去年に比べて集中力が切れやすくなった。体のマネージメントが必要。
- (その他)会場にタクシーで向かう
→間違ったバスに乗ってしまったため降りてタクシーで向かうことに。
→そもそも会場に駐輪場あったので自転車で行けた。
パイロット ボールペン フリクションボール LFBK230EF10C 10色セット cyamax.hateblo.jp
今回の投資
受験代 5,700円
参考書代 2,580円 + 3,700円
タクシー代 1,220円
勉強時間 60時間
計・・・13,200円 + α
次回どうするか
ここで諦めては勉強時間や投資が意味ないので、来年春また受験します。
来年の受験に向けて自分へのメモ。
試験対策は1ヶ月前から絶対にやること。去年勉強やったからといってサボらないこと。
SQLを次はちゃんと勉強すること。今回は時間がなくて省いたけど次回は必須。
今回DBSの勉強は「敷居を下げる作業の繰り返し」と感じた。
時間をかけて考えたら解ける問題を繰り返し行うことで、
問題を解く作業の敷居を下げて、頭の余力を残し、
問題の本質にその余力を充てないといけない。
表面的な問題で頭をできるだけ使わないようにできるようにすること。
コマンドプロンプトでシェルを使う
どうなるのか
Windowsに標準で入っていながら、パワー不足によりあまり人気のないコマンドプロンプト。
産みの親のMSにも、これからはPowershellに力を入れていくからと言われてかわいそうな状態。
そのコマンドプロンプトをちょっとだけカッコよくしてみる。
これが
 こんな感じになったり、
こんな感じになったり、
 こんな感じにできる。
こんな感じにできる。

メリット
コマンドプロンプト打ちながら「シェル使いたいな」と思ったときにささっと切り替えれる。
コマンドプロンプトからvimやsshもできる。
コマンドプロンプトの画面だったのに急にシェルになるのが「なんとなくかっこいい」かもしれない。
手順
シェルのインストール
シェルとなるMSYS2をインストール(Cygwinでも可)します。
インストール方法は他の方が書いてくれているのでそちらを参考。
PATHを通す(ユーザ環境変数を追加する)
コマンドプロンプトからシェルのコマンドを使えるようにします。
以下コマンドでユーザの環境変数にmsysへのPATHを追加します。
SETX PATH "%PATH%;C:\msys64\usr\bin" 成功: 指定した値は保存されました。
確認
これで基本的なシェルのコマンドが使えるようになった。
コマンドプロンプトを起動して、 lsやvim、bashを打つと実行される。
ちなみに
zshはこんな感じ。

応用
powershellでもそのまま使えるよ
PATHが通っているのでPowershellでも同じように使える。
powershell版のSSHモジュールとかインストールしなくても使える。

Visual Studio Codeのターミナルでも使えるよ
もともとはこれがしたくてやりました。

iphoneのスピーカーが壊れたけど、3時間後には修理完了した話

iphoneのスピーカーが壊れた
半年前に買ったiPhoneがおかしくなった。
初めは音楽を聴いていると高音で音割れし始めて、
1ヶ月前から音がでたり出なくなったりした。
そして3日ほど前から完全に音が出なくなった。
外にいる時は困らないけど、家にいるとき音楽を聴いたり動画見るときに音が出なくて不便になってきた。
修理の手段や値段がわからない
iPhoneを3GS時代から機種変更を繰り返して使ってきたが、
それまで一度も壊れたことがなかったので、
Apple careやキャリアのサポートには入っていなかった。
ネットで調べると非公認業者のスピーカー修理は5,000〜10,000円が相場らしい。
正直5000円あったらRaspberryPi Zero Wを5個買いたい。そっちにお金を使いたい。
壊れたiphoneをソフトバンクの窓口に行っても、混んでそうだしサポート入っていないから有償になりそう。
かといってAppleサポートに電話しても繋がるまでに1時間ぐらいかかるしどうしようと考えていたら、
Appleのサポートを電話ではなくチャットする方法があった。
Appleサポートとチャットする
待ち時間ゼロでWEB画面上でチャットが始まった。※iphoneからでもOK
事情を説明してどうすれば良いか尋ねたら、
私の場合はハードウェアの故障の可能性が高く、落下による破損や水没がなければタダで修理できると教えてくれた。
そして家の近くのapple修理代理店と予約空き情報を調べてくれて、そのまま予約してくれた。
チャット自体は10分ぐらいで終わり、
予約した時間に代理店に行くと、非常に混んでいたがすでに話が通っているのでスムーズにやり取りが進む。
そして代理店に行ってから1時間後にはスピーカーのパーツを交換して無事修理が完了した。
修理について調べてから3時間後にはiphoneが直ったのは嬉しい。
まとめ
Appleに用があるときは電話じゃなくてチャットが良いよ。
Google SpreadSheetsで効率的に転職先を探す
少し前にはてなランキングでGoogle Spreadsheetsを使った物件探しの記事が上位に来ていた。
記事を見たときに自分も似たようなことを昔やったなと思い出したので、
転職活動中orしようと思っている方々向けに記載。
知りたいこと
合同企業説明会や求人情報を見たときに、企業がたくさんありすぎて大変だった。
会社名だけではさっぱりなので以下のことは知りたい。
・業種
・勤務先
・年収
・従業員数
・評判
検索サイト
会社の評判が見れるサイトはたくさんありますが、
「転職会議」を使わさせてもらいました。
検索がダルかった

求人情報や企業説明会は毎回100社ぐらい会社名が出てくるので、一つずつ調べるのがめっちゃダルい。
なのでGoogle SpreadSheetsのimportxmlを使ってスクレイピングして効率的に情報を収集した。
会社名は合同企業説明会や求人サイトからコピペで一気に持ってこれるので、
あとはSpreadSheetsに貼るだけで情報を引っ張ってくれる。
使い方
以下シートを自分のGoogke SpreadSheetsにコピーして使ってください。
A列に会社名を入れれば「転職会議」で検索した情報と同じ情報を引っ張ってきます。
「検索した会社名が複数ある可能性があります」と出る場合は、
転職会議検索のリンクをクリックして確認してください。
検索用に以下変換も付いています。
(株)→株式会社
【株】→株式会社
あとは自分好みに改造すると幸せになれると思います。
docs.google.com
その他
私が転職活動をした2015年は「vorkers」からも情報を取れたのですが、
今はimportxmlでは取れなくなっていたので上記SpreadSheetsから消しました。(User-Agentの値をみてそうです)
詳しい会社情報や口コミ情報はちゃんと「転職会議」の会員になってログインして見ましょう。
新生児の泣いている原因と見極めかた
子供が生まれました

初めての娘が生まれて1ヶ月が経ちました。
初めは5時間泣きっぱなしだったり大変でしたが、注意深く観察していくうちに
泣いているのにはちゃんと理由があることに気づきました。
いま子供(新生児)が泣いて困っている人がいたら参考になるかなと、気づいたことを書いていきたいと思います。 ※私の1ヶ月の経験と助産師さんのアドバイスが混ざっているので信じすぎず参考程度に見てください
赤ちゃんが泣いている原因
腹減った
夜泣きが最初の3週間酷かったですが、ほとんどの原因がこれでした。
我が家の場合ミルクで育てていたので3時間ごとでないと飲ませられなかったのですが、
与える量が少ないと3時間よりも早く起きて泣き始めます。
「ミルクまであと1.5時間ある。どうしよう・・・」
となってあやしてみるものの、お腹がすいているので泣き続けます。
しょうがないから30mlだけ与えてもこれは意味がありません。
最初のミルクから1.5時間経ってお腹が空いて泣いているので、
30mlだけ飲んでも足りないので泣き続けます。
母乳とミルクの両方でやっている人は、産婦人科から「ミルクは○mlまで!」と言われる場合があります。
母乳を途中でやめた場合はミルクを適切な量にする必要があります。
見極めかた
泣いている時に口や舌がペロペロ動く。
口に指を近づけた時の食いつきがいつもよりもすごい。
体重が数日増えていない。
うんちが24時間以上出ていない。
対応方法
ミルク缶に書いてある適切な量を確認する。
決められた量を飲ませて2時間で起きてしまうようであれば、少し多めに作って赤ちゃんがどこまで飲むか見てみる。
個体差はあるので飲む子は飲む。
多めに飲ませて長く寝てくれるようであれば、ミルクの量や質を確認してみる。
また深夜のミルクは昼間よりミルクの量を欲しがる傾向があるので少し多めにしてみる。
かゆい
生後1週間がたったころ、赤ちゃんからチーズの臭いがしてきました。
こんなものなのかなと思っていたら、実は吐いたミルクが首のシワに溜まって発酵していました。
首元の皮膚も赤くただれていました。
赤ちゃんの首は奥深くまでシワがあるので沐浴のときによーーーく確認して丁寧に綺麗にしてあげましょう。
見極め方
チーズくさい
首の奥の皮膚がただれている
対応方法
丁寧に優しく洗ってあげる。
酷いようであればちゃんと先生に相談。
オムツが気持ち悪い
これが原因が泣くことはあまりなかったです。
泣くよりはグズグズ言うことが多いです。
お腹が気持ち悪い
飲んですぐに横にすると気持ち悪くて泣き出します。
見極め方
ミルク後に泣いた場合、縦にすると大人しくなる。
対応方法
げっぷをさせる。
10分ほど縦に抱っこしたあとに、横にする。
眠い
上記の何かしらの原因で不満があり、寝たいに寝れなくて怒って泣きます。
だっこして・かまって
だっこすると一時的に泣き止むので、頑張ってあやしたりしますが、
すぐ泣き出す場合は、別の原因の可能性が高いです。
あまり「だっこしてーーーーー!!!!」とはならない。
寒い・暑い
相当ひどくなければあまり泣くことはないですが、 我が家の場合は暑くてぐったりしていました。 こまめに様子を見てあげましょう。
赤ちゃんのマジ泣きアナライズ
赤ちゃんがマジ泣きしたときの声が頭にキンキン響くので、
泣き声をスペクトルアナライズしてみた。
昔はMatlabでやっていましたが、
個人だとライセンスが高いのでpythonでやってみました。
取得方法
Macbook airの標準搭載のマイクを利用
python3 pyaudioモジュールでストリーミングを取得
ストリーミングのデータを高速フーリエ変換
pyqtでグラフを高速表示させることで、リアルタイムスペクトルアナライザを実現
スペクトル結果
テレビの砂嵐のとき
赤ちゃんが聞くと泣き止むというアナログテレビの砂嵐音。
この音はホワイトノイズに似ていて各周波数ある程度スペクトルが立っています。
一番高い周波数が1500Hzぐらいなので聞いていても不快感はない。

横軸:Hz、縦軸:強さ
「shi」のとき
口で「shi」の音を出した時のスペクトル。
この音もホワイトノイズに近いかなと思い測定してみました。
赤ちゃんにこの音を聞かせると落ち着いてくれるので、最近はずっと「しーっ」と言っている。
誰かが「しーっ」と言うと自然と静かになるのは、大人でも子供でも外国でも共通だと信じています。
2500Hzとその倍音の5000Hzにピークがあるようです。
日本語の中でだいぶ高い周波数。※これよりも高い五十音はあるのかな

横軸:Hz、縦軸:強さ
赤ちゃんのマジ泣きのとき
はい、スペクトルが振り切れました。
音量もすごいですが、高音帯域のスペクトルが高いので耳鳴りのように聞こえる。

横軸:Hz、縦軸:強さ
まとめ
赤ちゃんの泣き声は高周波満載。
日常会話で使う周波数は250Hz〜4000Hzなので、それと比べるととても高いのがわかる。
感想
マイクデバイスにリアルタイムで処理する方法がわかったので、いろいろ発展したものができそう。 ただグラフはpythonのpyqtを使ってみましたが、対数表示にしたかったけどスケール調整の方法がわからなかったので見づらくなってしまった。
学生時代に研究室で教授の話し声がうるさかったので、
マイクから拾った音の逆位相をイヤホンから出し、声を打ち消すノイズキャンセラを作ろうとしたことがありますが、
当時は処理速度が間に合わなくてただイヤホンからも教授の声がする声増幅器になってしまいました。
今のPCスペックならお手製のノイズキャンセラを作ることができるかもしれないですね。

安価なホームルータを高機能ルータに改造する

経緯
Debianの対応アーキテクチャを眺めていたら、様々なCPUに対応していることに気がつく。
無線ルータのCPUアーキテクチャにOSが対応していたらLinuxをインストールできて面白そう。
DD-WRTとは
調べると「DD-WRT」 というものを発見。すでにあるのね。
無線ルータのファームウェアを書き換えることで安価なホームルータも
ハイエンドモデルの機能ができるようです。
DD-Wrtは、ゲートウェイ、無線LANアクセスポイントなどの組み込みシステム用ファームウェアとして開発されているLinuxディストリビューションの一種である。OpenWRTを元にして作られている。組み込みシステムはパソコンとは違い、規格が統一されていないため、各製品毎に対応が図られている。各製品毎の対応状況は、公式サイトの"Router Database"で型番から検索して確認することが出来る。家庭用ルーターの非公式ファームウェアの中では最も有名である。
DD-WRT公式ページ
どんなことができるのか
以下のページにまとまっていますが、
・OpenVPNサーバ
・イーサネットコンバータ
・DDNS
・VLAN
などなど
8年前に3000円で買った眠ってたバッファロールータが超高機能になりそうな予感。
ファームウェアを書換える
やり方はルータによって異なる&調べたら色々出てくるので割愛しますが、
バッファロー製ルータなどがやりやすいようです。
私のバッファロールータ(WHR-HP-GN)はDD-WRTからファームウェアをダウンロードして、
既存の設定ページからファームウェアのデータを上書きするだけでできました。
注意
ダウンロードしたファームウェアを適応すると初期設定では出力電波が最大になっています。
日本では電波法違反になったりと色々注意することがあるので、ちゃんと調べてから実施しましょう。
やったこと
公式ページで自分のルータを検索してダウンロード
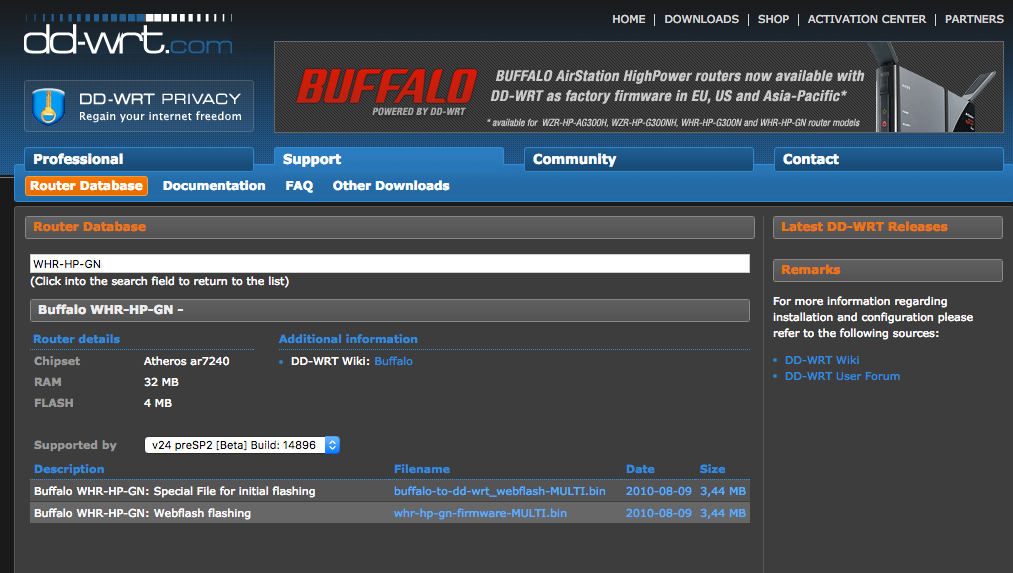
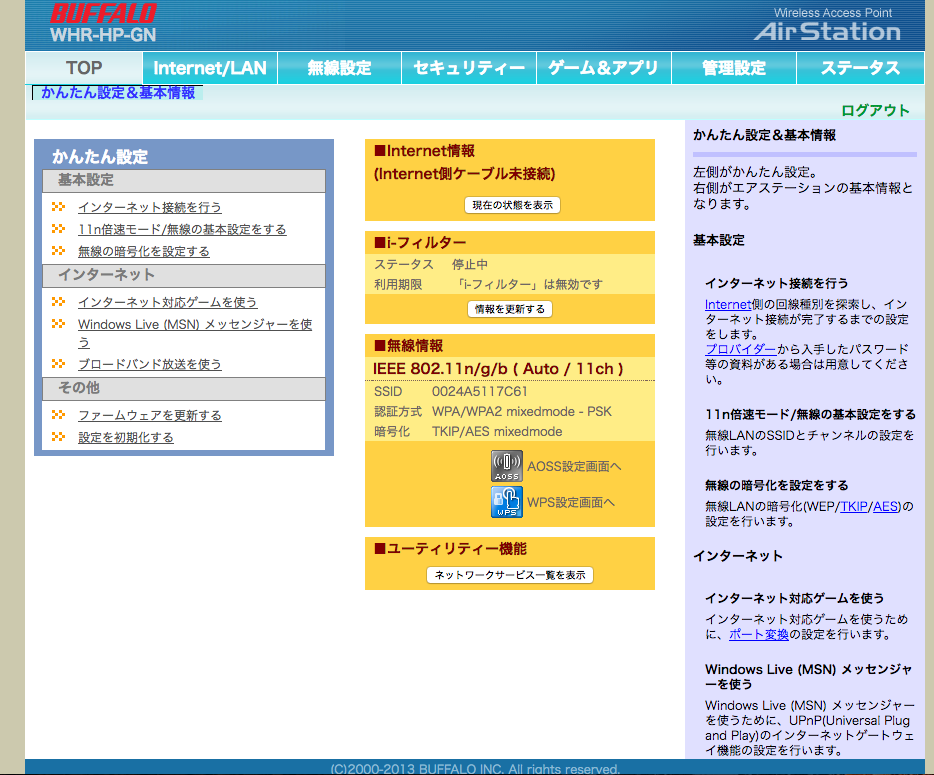
既存のバッファロールータの管理画面
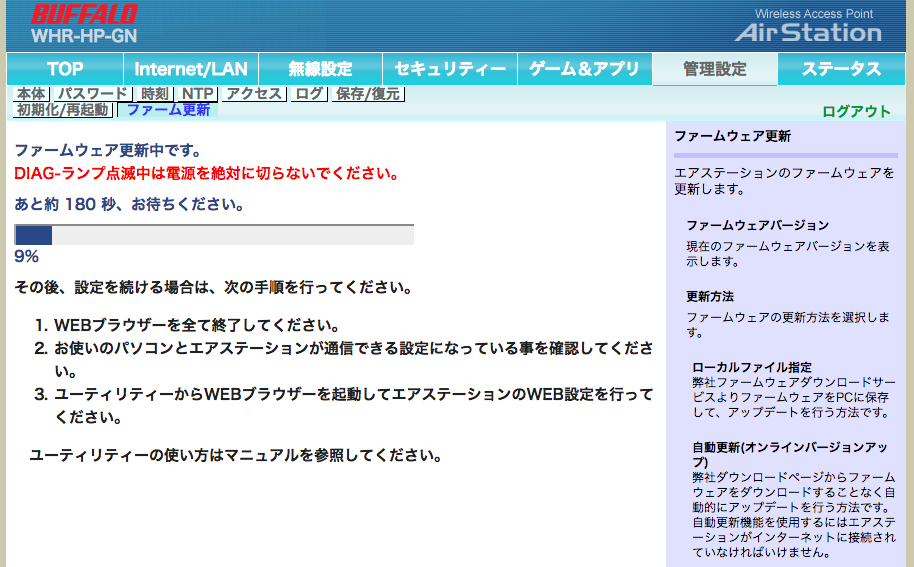
ファームウェア更新画面でダウンロードしたファームウェアを選択
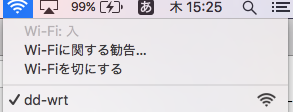
再起動後、無線が繋がらなくなる。
そして知らないdd-wrtというSSIDが鍵なしで出てきた。
デフォルトで192.168.1.1.にアクセス。
先ほどとは違う管理画面が出てくる。
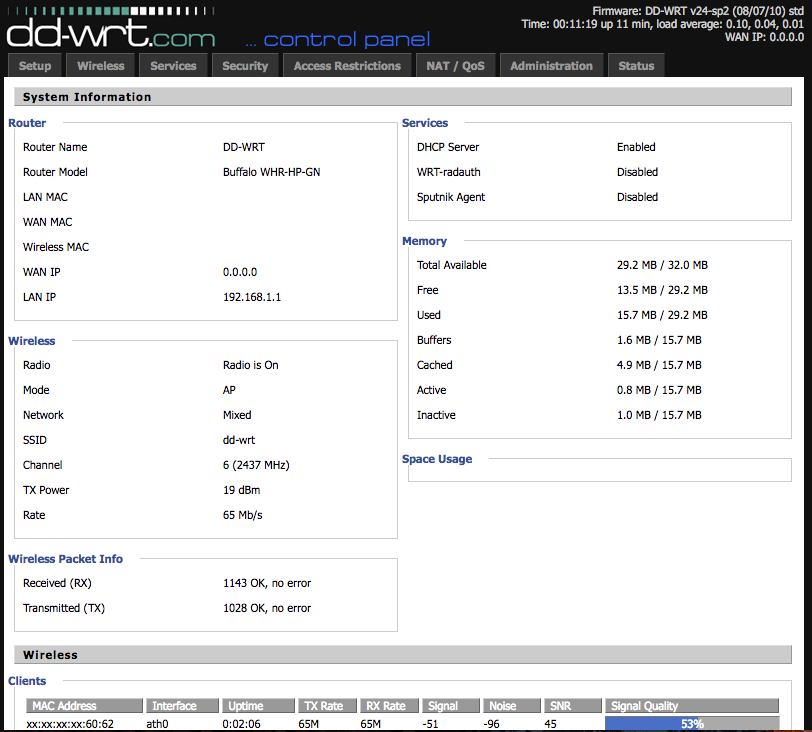
日本語化や電波強度など設定を終えて、接続してみる。
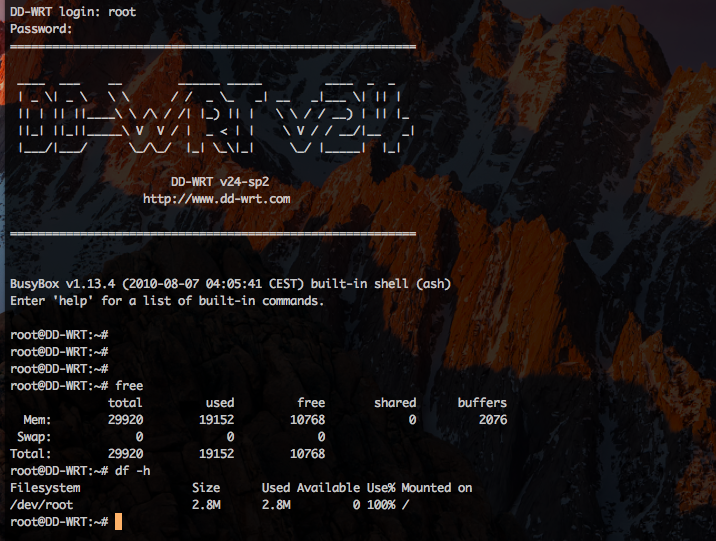
元々ssh、telnetできないルータだったのでこれだけでも面白い。
ルータなのでメモリや容量は小さめ。
CPUを確認してみる。
cat /proc/cpuinfo
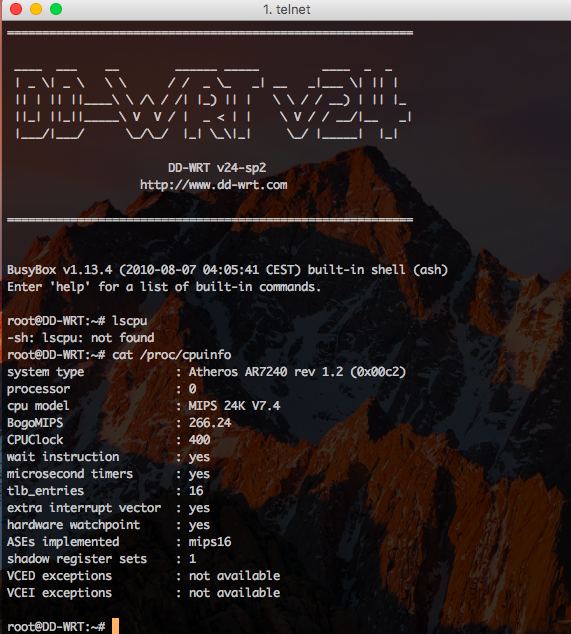
最近のルータはMIPSのSoC(System on Chip)構成が多いようです。
SoC構成だと汎用的なCPUが使われることが多いのかな?
Linuxがインストールできるものが増えてきそうですね。
RaspberryPiで家の騒音をグラフ化
赤ちゃんがいつ泣いているのかログを取りたい
 1日何時間泣いているのかや、
1日何時間泣いているのかや、
何時頃に泣くなど傾向がわかったら面白そうなのでやってみました。
用意するもの
- RaspberryPi 2 or 3
- USBマイク
環境準備
Elasticsearch×kibana×Fluentdのインストール
グラフ化するために以下環境を用意します cyamax.hateblo.jp
Python3のインストール
Pythonは2系と3系がありますが、今後主流になっていく3系を使います。
普通はpyenvやvenvを挟んで環境を切り替えることが多いですが、
RaspberryPi上だとうまくできなかったので、
シンプルに直接Python3系とモジュールをインストールします。
$ sudo apt-get install python3 python3-numpy python3-pyaudio
マイクデバイスの認識
こちらのサイトにマイクデバイスの設定方法が書いてあるので、参考にさせていただきました。 karaage.hatenadiary.jp
設定後以下のようにUSBデバイスが優先されていればOKだとおもいます
$ cat /proc/asound/modules 0 snd_usb_audio 1 snd_bcm2835
マイクのサンプリング周波数を確認
マイクから信号を受け取りにあたりサンプリング周波数を設定する必要があります。
マイクに合った設定をしないとエラーが出て取得できません。
サンプリング周波数はUSBマイクを一度Macに挿して
システム情報->ハードウェア->オーディオ->デバイス
にUSB PnP Sound Deviceの欄で確認できました。
※Windowsの場合は試していませんがデバイスマネージャなどから確認できるかもしれません

騒音をログ化する
動作のながれ
- マイクからのストリーミングデータをCHUNK分(1024*2)ずつ抜き出してその中で最大振幅を配列max_dataに入れる。
- Thredingを使って指定時間ごとに割り込み処理(sendlog)を実行
- 割り込み処理では配列max_dataの平均値を計算してFluentdに送り、max_dataを初期化
Pythonでの割り込み処理はThredingモジュールで実装
Fluentdへはsubprocessでechoを使って実装
コード
# -*- coding:utf-8 -*- import pyaudio import numpy as np import threading import subprocess max_data=[] CHUNK=1024*2 # マイクによって変わる。上手くいかない場合色々試してください RATE=48000 # 事前に確認したサンプリング周波数 p=pyaudio.PyAudio() stream=p.open(format = pyaudio.paInt16, channels = 1, rate = RATE, frames_per_buffer = CHUNK, input = True, output = True) def audio_trans(input): frames=(np.frombuffer(input,dtype="int16")) max_data.append(max(frames)) return def sendlog(): # 定期的に呼び出される global max_data if len(max_data) != 0: # 初回実行時だけ無視 mic_ave=int(sum(max_data)/len(max_data)) # 60秒間のマイク受信音量の平均値を出す max_data=[] #print("スレッドの数: " + str(threading.activeCount())+threading.currentThread().getName()) #Thredingでプロセスが乱立しないかチェック用 ## fluentdに最大音量値を渡す json = '{'+'\"mic_max\":{0}'.format(mic_ave)+'}' cmd = "echo '" + json + "' | /usr/local/bin/fluent-cat log.hoge" try: print (cmd) res = subprocess.check_call(cmd, shell=True ) except: print ("error") t=threading.Timer(60,sendlog) #60秒ごとにsendlogを実行 t.start() t=threading.Thread(target=sendlog) t.start() print ("mic on") while stream.is_active(): input = stream.read(CHUNK) input = audio_trans(input) stream.stop_stream() stream.close() p.terminate() print ("Stop Streaming")
実行結果
 1、2時間ごと夜泣きをしてそのタイミングでグラフが上昇。
1、2時間ごと夜泣きをしてそのタイミングでグラフが上昇。
朝方を過ぎた頃に子供を移動させたのとテレビをつけたので全体的に平坦になっているわかる。
感想
マイクの受信感度やメモリ管理などまだまだ調整する箇所はありますが、
やりたいことはできた感じ。
マイクはベビーベッドに設置してましたが、
泣いたタイミングで抱っこして違う部屋であやしたりしていたので、
数値の大きさはあまり当てにならない結果になってしまいました。
※上昇タイミングだけ意味のあるデータとなった
参考サイト
Raspberry Pi 2で音声認識・音声合成してみる - karaage. [からあげ]
PyAudioの基本メモ2 音声入出力 - たけし備忘録
python - Pythonのthreading.Timerで定期的に処理を呼び出すサンプル - スタック・オーバーフロー
RaspberryPiのCPU温度、電圧、クロック数をElasticsearchに送ってグラフ化
ログの可視化
せっかくelasticsearch×kibana×fluentdの環境を構築したので、
データを入れていきます。
準備
以下の手順で環境を準備します。 cyamax.hateblo.jp
CPU温度、電圧、クロック数の取得
以下の公式?サイトに載っていました。 RPI vcgencmd usage - eLinux.org
##CPU温度 vcgencmd measure_temp ##電圧 vcgencmd measure_volts ##クロック数 vcgencmd measure_clock arm
ただしこのままではグラフ化できません。 Elasticsearch側に送る必要があります。
JSONに整形
以下のスクリプトで取得したデータを整形&Elastisearchに送信をします。
crontabなどで5分ごとの定期実行させると良い感じになります。
#!/bin/bash #raspberryPiの情報をjsonに整形する ##CPU温度 ras_temp=`vcgencmd measure_temp |sed -e "s/temp=//" -e "s/'C//"` ##電圧 ras_volt=`vcgencmd measure_volts |sed -e "s/volt=//" -e "s/V//"` ##クロック数 ras_freq=`vcgencmd measure_clock arm |sed -e "s/frequency(45)=//"` #echo $ras_temp #echo $ras_volt #echo $ras_freq json_date={\"ras_temp\":$ras_temp,\"ras_volt\":$ras_volt,\"ras_freq\":$ras_freq} echo $json_date |/usr/local/bin/fluent-cat log.hoge
kibanaを見てみる
crontabで実行するごとにデータが送られて、
以下のようにkibana側で見ることができました。

電圧・クロック数が動的に変化
グラフ化して初めて知ったのですが、
RaspberryPiは入力電圧によって動作クロックが変わるようです。
私の環境ではRaspberryPiに繋いでいるUSBアダプタはiPhone用の1Aアダプタを使用し、
USBケーブルは60cmほどの長めのものを使っているので、
電圧が不安定になってしまっているのだと思います。
 電圧とクロックが上下していることがわかります
電圧とクロックが上下していることがわかります
まとめ
RaspberryPi上でデータ収集&グラフ化までできるようになりました。
次は別センサのデータを集めてみようと思います。