Google Docsのショートカット集
Google Docsのショートカット集
Google Docs(ドキュメント)のショートカット集を作成しました。
チートシート(Cheats Sheet)とも呼ばれています。

ダウンロード
PDFファイルのダウンロードはこちらからできます。
GoogleDocs_CheatsSheet.pdf
リポジトリ
間違いなどがあれば、Githubからプルリクをお願いします。
https://github.com/cyamax/cheats-sheets
更に速度を上げたい
仕事のスピードを上げたい方向け

参照元
PythonでTorを使用する(基本)

基本設定
実行環境
- Ubuntu 20.04LTS
- Tor version 0.4.2.7.
- Python 3.8.10
Torのインストール&実行
$ sudo apt install tor
- Torを一時的に使う(起動する)場合
$ tor
止めたい場合は、Ctrl + c
- Torを常時動かす場合
$ sudo service tor start
- Torを止める場合
$ sudo service tor stop
Pythonモジュールのインストール
$ pip install pysocks
pysocksを入れないと下記のエラーが出る。 pythonコード内ではimportしていないのでハマりポイント。
requests.exceptions.InvalidSchema: Missing dependencies for SOCKS support.
PythonからTor経由あり・なしでアクセスする
import requests # importは不要だがpysocksのモジュールを事前にインストールしておく必要あり proxies = { "http": "socks5://127.0.0.1:9050", "https": "socks5://127.0.0.1:9050" } # Torを使用した場合 print("Torあり") print(requests.get("http://httpbin.org/ip",proxies=proxies).text) # Torを使用していない場合 print("Torなし") print(requests.get("http://httpbin.org/ip").text)
chrome.storageをPromise(async/await)する
はじめに
Chrome拡張機能を作っていると、chrome.storage.sync か chrome.storage.localを使うことが良くある。
chrome.local.sync.get( date => { console.log(date) })
値取得時に簡単な処理なら良いが、複雑な処理を書くとネストが深くなりコールバック地獄になってしまうので、
Promise(async/await)を使って使いやすくする。
いつも使うので、自分用にテンプレートとして記載
書き方
準備
const getStorage = (key = null) => new Promise(resolve => { chrome.storage.local.get(key, (data) => {resolve(data)}); }); // 省略形 const getStorage = (key = null) => new Promise(resolve => { chrome.storage.local.get(key, resolve)}) });
取得時
thenの場合
getStorage().then((data) => {console.log(data)})
async/awaitの場合
(async () => { let a = await getStorage(); console.log(a); // })();
chrome拡張機能のストレージへの容量増加と中身の確認
ストレージを増やす
Chrome拡張機能を開発中に、急にデータの保存が効かなくなり以下のエラーが出ていた。
Unchecked runtime.lastError: QUOTA_BYTES quota exceeded
もともとchrom.storage.sync.setで保存していたのだが、どうやら一つのキーに対して保存できるのは8KBまでらしく、
それ以上の保存をしたい場合、保存先の変更と拡張が必要らしい。
拡張方法
作成しているchrome拡張機能のmanifest.jsonのpermissionsにunlimitedStorageを追加する。
"permissions": [
"storage",
"unlimitedStorage"
],
そして、chrome.storage.sync→chrome.storage.localに変更
//chrome.storage.sync.set({ key: value})
chrome.storage.local.set({ key: value})
これで同期機能は使えなくなったが、8KB上限はなくなった。
ストレージを確認する拡張機能を使う
今まで保存した内容を確認するのに以下のようなコードを打っていたが、
毎回打つのは面倒だし、使い勝手は良くなかった。
chrome.storage.sync.get(null, ((data) => {console.log(data)}));
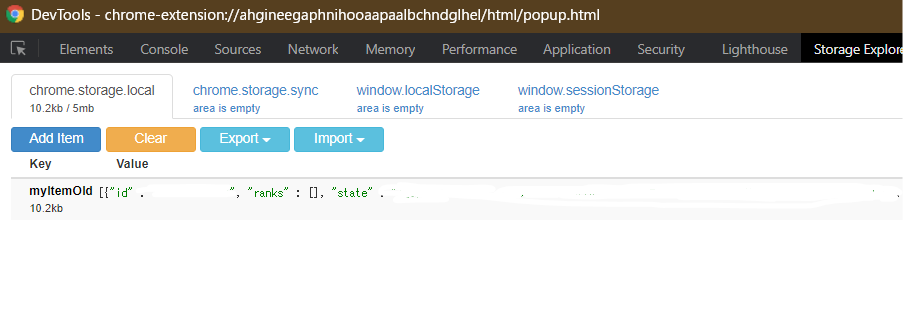
調べてみるとchrome.storageを確認する拡張機能を見つけた。
コンソール画面から遷移して確認するが、コードを打たなくて良いのでかなり楽である。
テスト駆動Python:環境構築~Chapter1:技術書メモ

読み進めた本
テスト駆動Python

- 作者:BrianOkken
- 発売日: 2018/08/29
- メディア: Kindle版
pytest とは何か
- ソフトウェアテストフレームワーク。
- 既存の unittest/nose などと比較して、テストが読みやすい。
- 単純なテストを書くのが簡単。
- 複雑なテストを書くのも簡単。
- unittest/nose のテストを pytest でも実行できる。
サンプルソース
本書のコードは公開されている。 ※もちろんこれだけでは意味が分からないので、本の購入は必要。 https://pragprog.com/titles/bopytest
本書のサンプルコードを実行するにあたり作成した環境
私個人の実行環境であり、本の内容とは関係ない。 Windows の WSL2 環境で検証。 WSL2 の中身は Ubuntu。
$ cat /etc/os-release NAME="Ubuntu" VERSION="20.04.1 LTS (Focal Fossa)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 20.04.1 LTS" VERSION_ID="20.04"
$ python -V;pipenv --version;pytest --version Python 3.8.2 pipenv, version 2020.8.13 pytest 6.1.0
pipenv を利用した仮想環境の場合
各個人の環境に依存。
私の場合は、今回はpipenvを利用して仮想環境を構築した。
$ pip3 install pipenv --user $ pipenv install pytest
##### pipenv の設定 ##### #.bashrc/.zshrcなどに追記する ## pipをユーザ権限でインストールしたときのライブラリの保存先にPathを通す export PATH="$PATH:$HOME/.local/bin" ## pipenvで仮想環境を作るときにproject配下に.venvを作成 export PIPENV_VENV_IN_PROJECT=1
VSCode の設定
本書ではpytestのコマンドでテストを実行させていたが、VSCode の GUI でも実行できるためそちらを試した。
pytest を VSCode から実行できるようにする。
コマンドパレット(ctrl+shift+p)からpython configure testsを入力して設定を開く。

どのテストライブラリを利用するか選択。今回は本と同じ pytest を選択。

どこに test ファイルがあるのかを選択。

Chapter1 はじめての pytest
左側にフラスコのアイコンが現れるので、そこをクリックし、Run All Testsボタンを押下するとテストが実行される。

ターミナル(ctrl+shift+@)のPROGRAMSのタブにより具体的な結果が表示される。

show test output からtest_failingを確認することができる。
※test_failingはなぜ失敗したのかの詳細セクション


assertについて
assertの後にbool値を返す式を書く。
def test_check():
t = 1
assert 1 == t
assert (1, 2, 3) == (t, 2, 3)
サンプルコードの"namedtuple"について
例としてnamedtupleを使っていたが、知らない関数だったので調べた。
https://qiita.com/Seny/items/add4d03876f505442136
## こんな風に使う
>>> from collections import namedtuple
>>> Car = namedtuple('Car' , 'color mileage')
## 出力
>>> my_car = Car('red', 3812.4)
>>> my_car.color
'red'
>>> my_car.mileage
3812.4
※qiita から抜粋
雰囲気だけ理解して、本質ではないので次に進む。
サンプルコードでやっていること
Task オブジェクトを作成して、その挙動を test 関数を使って検証している。
from collections import namedtuple
# Taskというデータ型のフィールド'summary', 'owner', 'done', 'id'を定義
Task = namedtuple('Task', ['summary', 'owner', 'done', 'id'])
# デフォルト値を定義
Task.__new__.__defaults__ = (None, None, False, None)
# パラメータを指定しないときのデフォルト値(t1)がt2と一致するかのテスト
def test_defaults():
t1 = Task()
t2 = Task(None, None, False, None)
assert t1 == t2
# namedtupleの.フィールド名が一致しているかテスト
def test_member_access():
t = Task('buy milk', 'brian')
assert t.summary == 'buy milk'
assert t.owner == 'brian'
assert (t.done, t.id) == (False, None)
pytest のオプション(紹介があったものだけ)
- -v, --verbose
- --collect-only
- -k EXPRESSION
- -m MARKERXPR
- -x, --exitfirst
- --maxfail=num
- -s, --capture=method
- --lf, --last-failed
- --ff, --failed-first
- -q, --quite
- -l, --showlocals
- --tb=style
- --durations=N
- --version
- -h, --help
ディスカバリルール(実行するテストとして認識させるためのルール)
- テストファイルは test_~~~ .py か ~~~_test.py 名前でないといけない。
- テストメソッド、関数は test_~~~ でないといけない。( ~~テストはダメ?)
- テストクラスは Test~~~ でないといけない。( ~~テストはダメ?)
pytestを引数なしで実行すると、上記のルールで書かれたファイル、関数、メソッド、クラスを探索されてテストコードが実行される。
感想
TDD がどんな感じなのか、雰囲気を理解した。続きは読み次第追記。
書籍
- 作者:BrianOkken
- 発売日: 2018/08/29
- メディア: Kindle版
MacbookProに4Kモニタを2台繋いで在宅環境を強化する
はじめに

結論
27インチ2画面運用はやめとけ。
2枚のディスプレイは視界に入りきらないし、首が痛くなる。
もくじ
この記事を書いている人
製造業のデータサイエンティスト。
コロナの影響で在宅勤務になり、今は家で仕事をしています。
仕事と個人の作業効率が上がりそうと思い、ディスプレイを購入しました。決して社畜だから買ったわけではありません。
PCの用途
仕事では大量のデータを眺めたり、コーディングを行っています。なので、Excelなどデータを見るときは表示できる列数が多い方が助かるし、
データを観ながらコーディングをするので、広い画面の方が捗ります。
今まではSlackやTeamsのようなコミュニケーションツールとメール/カレンダーも開きつつ、データもみて、webサイト調べながらコーディングして、、テストの結果見て・・・と都度画面を切り替えて使っていました。
モニターを買う大義名分
きっかけはコロナによる在宅勤務ですが、価値観の変化によるものもあります。 自宅の環境をよくすれば仕事も趣味の開発も効率を上げることができる。 仕事の効率が上がれば、家族や趣味に使える時間が増え、開発もより短い時間で効果が出せるので、投資効果が高いと判断しました。
自宅環境への投資効果が高いことにはすぐ気づけましたが、その後どのディスプレイを買うかにかなりの時間を使ってしまいました。
買うまでの話
これまでの環境
デスクトップPCは持っておらず、仕事ではThinkpad X1 carbon、個人ではMacbook Pro 13inch (2016Late)を利用。
ノートPCスタンドを利用していましたが、外部モニターとノートPCの画面サイズが違いすぎて違和感がありました。

既に4Kモニターは持っていたが、疲れるので買い替えたい。
 ノートPCスタンドと併用して4K24インチモニターをこんな感じに3年間使っていましたが、安物のせいか長時間の作業をすると非常に疲れました。
ノートPCスタンドと併用して4K24インチモニターをこんな感じに3年間使っていましたが、安物のせいか長時間の作業をすると非常に疲れました。
普通に考えれば、4K2画面にしたいのであればこれと同じ4Kを買うのが一番安上がりなんですが、上記の理由からもう一台買おうという気にはなりませんでした。
損をしたくないからかなり迷ったけど、長い時間迷っている方が損だった
新しいモニターを買おうと思ったのですが、ここからが非常に迷いました。
- ノートPCで使うし、デスクをスッキリさせたいからtype-cによるPowerDelivery付きの方がよい?
- USBハブ機能はあったほうがよい?
- 4K2枚ではなくウルトラワイドモニタという選択肢はどうか?
- 湾曲ディスプレイも良さそう
- というか、デスクトップPCを買ったほうが処理スピード上がって効果的では?
- そもそもノートPCで8K出力はできるのか?
トータル3週間ぐらい迷ったと思います。しかも結構な時間をかけて調べていました。
そして気づきました。
この悩んでいる時間を自分の時間単価で計算すると、すでに4Kモニターを変えるくらいの時間を使っている・・・。
しかも私生活や仕事中にモニターのことを考えてしまって集中力や能率にも悪影響を及ぼしている。
考える時間が増えるほど、自分にマイナスと判断したので、以下のように必要機能を絞り込み、4Kの購入に踏み切りました。
購入の目的:作業の効率を上げたい。身体への負担を軽減したい
検討事項
- ノートPCで使うし、デスクをスッキリさせたいからtype-cによる電源供給付き&USBハブ付きの方がよい?
- ケーブルの抜き差しの頻度は多くない。電源供給付きは2万ほど高くなるが、ケーブルが一本減ることで差額の2万円分の投資効果がでるとは考えられない。→不要と判断。
- 4K2枚ではなくウルトラワイドモニタという選択肢はどうか?
- 解像度で考えたときに、表示できる情報量がフルHD2枚よりも少ない→却下。
- 湾曲ディスプレイも良さそう
- 湾曲ディスプレイの高解像度ディスプレイは種類が少なくコスパが悪い。また、画面が湾曲していることにより直線が歪むため、資料作りやWEBサイトのデザインなどに悪影響が出ると判断→却下。
買ったあとの話
実際に買った4Kディスプレイ
色々考えた結果、以下のディスプレイを買いました。2020年6月時点では4万5千円ぐらいだったと思います。
LG モニター ディスプレイ 27UL650-W 27インチ


ベゼルはかなり狭い

見えないところですが、背面は白色です。

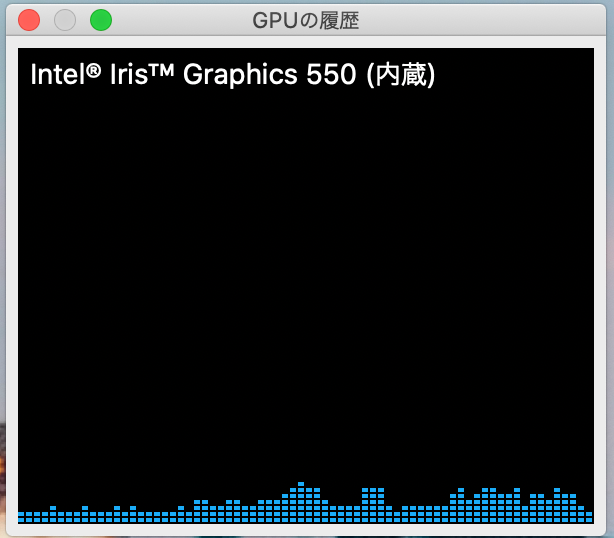
GPUの負荷はそこまで高くなかった
GPUの負荷率をWindwos,MacBookProの両方でみてみましたが、逼迫するほど使用率が高いというわけではありませんでした(もちろんPCのスペックによると思います)。
MacBookProで4K2画面接続&Youtubeを再生したときのGPU使用率
24インチ→27インチにして良かった
24インチ4Kと27インチ4Kの違いですが使用感はかなり違いました。 一番感じたのは画面の3分の1分割でも辛くないという点です。 横方向に3分割したとき、実用的なのは27インチです。 24インチでも3分割利用はできますが、文字が小さすぎので身体への負担は大きかったです。
画面が広くなった
当たり前過ぎるので書かなくても良いかもしれませんが、広くなりました。意味がわからないかもしれませんが、1ルームから2LDKに引っ越して部屋が少し余る感覚と近いかもしれません。
すべて画面上に表示されているので、通知が来る度に画面を切り替えたり最小化や最大化をする頻度が減りました。作業に集中できるようになりました。
24インチと27インチの構成でも多分問題なかった
ここまで書いてあれですが、27インチで2枚揃えたのはやりすぎだった感はあります。 元々持っていた24インチを補助的なモニターにして27インチをメインとして使っても全然良かったと思います。 左右に同じディスプレイを並べたいという非合理的な感情で買い揃えてしまった感はありますが 「やっぱり2枚買い揃えておけばよかったかな」と後々後悔したくなかったので、バシッと買い揃えました。 あと、同じ型番のディスプレイでも工場や時期によって色合いが異なることがあるらしいので同時購入しました。
27インチの縦置きはおすすめしない
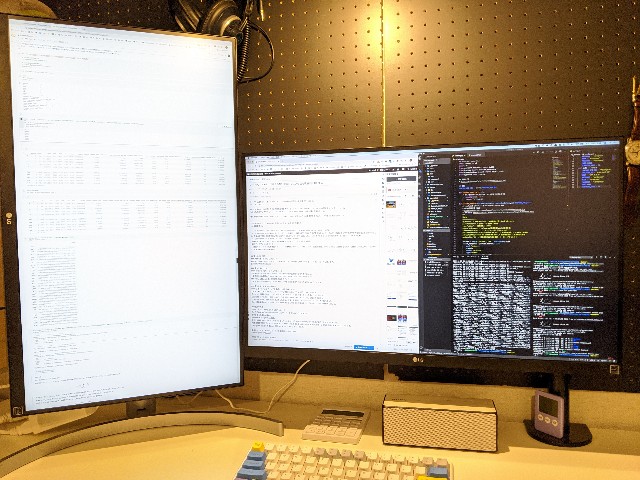
人間の目は縦方向の視野角は狭いので、どうしても視界から外れます。また、メガネをかけているとメガネのフレームとも被ってより見づらい気がしました。 以前、24インチの縦置きで使用していましたが、ぎりぎり使用範囲内でした。
気づいた点
ノートPCで8K出力しても意外といける
今から四年前ほどMacbook Pro2016 Lateのスペックでも8K出力できました。 今のところ不具合は無いです。
HDMIとDisplayPortの違い
デジタル信号なんだから同じだろうと思っていたのですが、HDMIとDisplayPortで色味が違うことに気づきました。 PC側の対応状況やプロファイルの設定、HDMIケーブルの条件等が揃わないとHDMI出力は100%の機能を発揮できないようです。 DisplayPortで出力した場合は、問題なくキレイに描写されていました。
MacbookProはType-cポートしかないので 以下のようなType-c to DisplayPortのケーブルを購入しました。
関係ないですが、布ケーブルって少し高級感があるので好きです。
![uni タイプC DisplayPort 変換ケーブル [ 4K@60Hz・2K@165Hz / USB-C DisplayPort / 1.8m ] Displayport USBC ケーブル, MacBook Pro Air / M1 Mac Mini/iMac iPad Pro Type-C デバイスに対応 [スペースグレー]](https://m.media-amazon.com/images/I/41MZa753UBL._SL500_.jpg "uni タイプC DisplayPort 変換ケーブル [ 4K@60Hz・2K@165Hz / USB-C DisplayPort / 1.8m ] Displayport USBC ケーブル, MacBook Pro Air / M1 Mac Mini/iMac iPad Pro Type-C デバイスに対応 [スペースグレー]")
リフレッシュレートの違い
上と同じようにHDMIとDisplayPortでリフレッシュレートが異なる場合があります。 私のMacbookProではHDMIでの4K@60Hzに対応していないので、HDMI接続したモニタ側のみ30Hzになっていました。 (DisplayPort接続では4K@60Hzに対応)
ディスプレイ購入前はDisplayPortの存在意義をよく分かっていませんでしたが、4K出力をする際はDisplayPort接続の方が無難なようです。 このあたりは同じディスプレイを並べて使わないと気づけない点だったので収穫でした。
購入時の注意点など
- モニターアーム(VESA)の対応有無
- 低価格帯のディスプレイは値段を下げるためにVESA非対応なものが多いです。後々アームを付けたくなったときに困るので、アームを付けたい人は要チェック。
- また、モニターアームのピンきりで2画面対応で3千円台のものもあれば、3万円(エルゴトロンなど)の高級品もあります。個人的にはモニターアームを毎日調節することはないので、安いモニターアームを購入して差額分をPCや椅子に回したほうが費用対高価が高いと思います。
")
")
- 液晶の種類
- 液晶の種類にはTN/VA/IPS/有機ELなどがあります。デザインや写真など視野角や発色重視ならIPS、ゲームなどの反応速度重視ならTN/VA などそれぞれ長所短所を 理解して選ぶ必要があります。私は作業用途なのでIPSにしました。
- type-cによる電力供給機(PowerDelivery)とUSBハブ機能
- モニターに付いたUSBポートにキーボードや外付けドライブを付けてtype-c経由でケーブルをまとめる事もできますが、動作が不安定なようです。また、上記の通りコスパの悪さから私は選びませんでした。USBハブ付きデュスプレイを2枚にして使うよりも以下のようなドッキングステーションの方が安い&機能も豊富&応用が効きやすいので良いと思います。
![CalDigit TS3 Plus/Thunderbolt Station 3 Plus/Thunderbolt 3 ドッキングステーション(スペースグレイ・0.7mケーブル付き)[TS3Plus-JP07-SG-AMZ]](https://m.media-amazon.com/images/I/31F1PrKWs3L._SL500_.jpg "CalDigit TS3 Plus/Thunderbolt Station 3 Plus/Thunderbolt 3 ドッキングステーション(スペースグレイ・0.7mケーブル付き)[TS3Plus-JP07-SG-AMZ]")
32インチの4Kのデュアルディスプレイはやめておいたほうが良い
- 27インチを2枚並べると視野角ギリギリです。これ以上大きい画面を並べると視界に収まらないので首を左右に振る事になり逆に使いづらいと思います。
ノートPCのファンがうるさいかも
- 8K出力でPCへの負荷が高い&クラムシェル利用なので、PCの温度は以前よりも上がり気味です。以前よりもファンが動いている時間が長くなったような気もします(部屋の温度にもよるかもしれませんが)。
まとめと感想
4Kのデュアルモニターはやってみて満足でしたが、結局首が痛くなってモニター一台+ノートPC運用に戻りました。 これは実際に買ってみない限りはわからないことだと思います、ロマン溢れる画面2つは実は使いづらいということは。
Macbook Proは一年間で価値がいくら下がるのか。
MacBookの値段が下がりづらいという話
Macbookは他のPCと比べて値段が落ちにくい(中古で売っても高く売れる)と言われていますが、
実際のところ年間いくら価値が下がるのかを中古市場の価格推移から計算したいと思います。
集計条件
- 情報源
- Yahooオークションの取引履歴
- 集計機器
- MacBookPro 2016 Late 以降のモデル(Type-C搭載モデルから)
- 集計期間
- 2015年6月 ~ 2019年11月までの取引
- 抽出条件
- 取引価格20,000円以上
- データ収集後のフィルタ条件
- ジャンク除外
- 出品タイトルに型番、CPU、メモリ、SSD容量を含むもののみ
取得した取引数は約64,000件となり、
上記フィルタに合致したのは、約2,000件となりました。
今回はこの2,000件を集計しています。
ばらつきについて
同じ型番の取引でも「オプションガジェット付き」だったり、傷の有無など価格に影響する要素が多数あり取引が同一条件ではありません。
傾向を分析するという意味で簡単なクレンジングはしていますが、プロットにばらつきがあるのは許容しています。
取引回数
各スペックと取引回数の表になります。2016年モデルはメモリ8G,SSD256GB、2017年モデルはメモリ16GBSSD128GBモデルの取引が多いことがわかります。
どちらもその年のモデルの中で最安値モデルなので、安いモデルが一番市場に出回っている事がわかります。

価格推移
価格推移については長期的な視点で確認するために、 十分な期間が経っているMacBookPro2016 Late モデル(集計時点で発売から3年経過)で分析しました。
一言にMacBookPro2016 Late モデルといっても、
13/15インチ、TouchBarあり/なし、メモリ、SSD、CPUなど様々な違いがあります。
ここでは一番大きな違い(公式のモデル区分)である、3タイプで分類しています。
- 13インチ2Port(TouchBarなし)
- TouchBarが無く、CPU,GPUがTocuhBarモデルよりもグレードが低い。
- 13インチ4Port(TouchBarあり)
- 15インチ4Port ※15インチにはTouchBarなしモデルは存在しない
モデル別取引価格推移
取引日と取引価格をプロットすると、予想通り発売日から日が経つにつれて取引価格が徐々に下がっていることが確認できました。
下がり方が直線的(1次関数)のように見えるので、さらに近似式(直線)を書いています。
線を引くとモデルによって傾きが違うことがわかります。この傾きが大きいほど、値段の下がる速度が早いことを表します。
以下の図では、13インチ2Port(TouchBarなし)が一番傾きが小さく、15インチ4Port が他と比べて値下がる速度が早いことがわかります。
値下がりの速度(傾きの大きさ)ですが、MacBookPro 2016 Late の場合は
- 13インチ2Port(TouchBarなし)
- 45円/日(16,425円/年)
- 13インチ4Port(TouchBarあり)
- 77円/日(28,105円/年)
- 15インチ
- 90円/日(32,850円/年)
という結果になりました。
これは、一日後には価値が45円下がっているという意味であり、
家にあるPCを売ろうとしたとき、一ヶ月待つと価値が1500円〜3000円ほど下がっているということになります。

モデル/メモリ別取引価格推移
同様にメモリ、SSDのスペックの違いによる価格推移を見てみます。
メモリ別価格推移
メモリを増設すると傾きが大きくなる(値下がる速度が上がる)ことがわかりました。
これはメモリだけではなく、SSDやCPUでも同様の傾向が確認できました。

取引の傾向
「新モデルが発表されると旧モデルが売りに出される」という仮設を検証するため、各モデルの取引数をグラフにしました。
2017年モデルが発売される直前に、2016年モデルの取引数が増えていることがわかりますが、他の年ではそこまで顕著な増加はないように見えます。
相関など出してみるとなにか傾向が見えてくる可能性があります。

まとめ
MacBookProの中古市場の値下がり傾向を調査しました。毎年一番安いモデルが多く市場に出回り、高スペックモデルになればなるほど、値下がる速度は早くなることがわかりました。 MacBookPro 2016 Lateの場合、値下がる速度は下記に示す値であり、2019年モデルなどでも同じような傾向になることが予想されます。
MacBookPro 2016 Lateの中古市場の値下がりスピード
- 13インチ2Port(TouchBarなし)
- 45円/日(16,425円/年)
- 13インチ4Port(TouchBarあり)
- 77円/日(28,105円/年)
- 15インチ
- 90円/日(32,850円/年)
この結果から、「MacBookは一番価値が下がりづらい最安値モデルを買えばいいんだ」と思うのは早合点です。
低スペックモデル(最安値モデル)と高スペックモデルでは値下がる速度が年間16,500円ほどの差がありますが、PCの処理スピードが違うので仕事の速さも変わってきます。
「毎日PCを触る人 or 重い処理をする人なら年間16,500円の違いで効率が変わるので、高スペックを買ったほうが良い」、
逆に「ほとんど触らない or ブラウジングしかしないという人であれば、最安値モデルが良い」ということが自分の時間単価と比較して数値から判断できそうです。
おまけ:テキストマイニング
オークションに出品されている出品タイトルをテキストマイニングしてみました。 いままでのフィルタ条件をなくし、"MacBook Pro"というタイトルを含む20,000円以上のオークションの取引をランダムでサンプリングしています。
以下サイトで簡単なテキストマイニングは無料でできます。
ワードクラウド
スコアが高い単語を複数選び出し、その値に応じた大きさで図示しています。 単語の色は品詞の種類で異なっており、青色が名詞、赤色が動詞、緑色が形容詞、灰色が感動詞を表しています。

単語出現頻度
文章中に出現する単語の頻出度を表にしています。単語ごとに表示されている「スコア」の大きさは、 与えられた文書の中でその単語がどれだけ特徴的であるかを表しています。 通常はその単語の出現回数が多いほどスコアが高くなりますが、 「言う」や「思う」など、どの文書にもよく現れる単語についてはスコアが低めになります。

共起キーワード
文章中に出現する単語の出現パターンが似たものを線で結んだ図です。出現数が多い語ほど大きく、また共起の程度が強いほど太い線で描画されます。

2次元マップ
文章中での出現傾向が似た単語ほど近く、似ていない単語ほど遠く配置されています。距離が近い単語はグループにまとめ、色分けしています。

階層的クラスタリング
文章中での出現傾向が似た単語をまとまりとしてとらえられるよう樹形図で表したものです。グループは色分けして表示しています。

 - スペースグレイ")
最新モデル Apple MacBook Pro (13インチPro, Touch Bar, 1.4GHzクアッドコアIntel Core i5, 8GB RAM, 128GB) - スペースグレイ
- 発売日: 2019/07/10
- メディア: Personal Computers
あいつ、セキュリティエンジニアやめるってよ
「やめるってよ」というか、2019年9月からセキュリティエンジニアをやめてデータサイエンティストになりました。
振り返りとセキュリティ対する成仏の意味を含めたポエムになります。
いままでのキャリア
大手携帯通信会社(非IT業務)
↓
IT系中小企業(情シス→社内セキュリティ担当:SIRT/SOC)
↓
大手製造業(社内セキュリティ担当→データサイエンティスト)
セキュリティエンジニアをやめた理由
一言にセキュリティエンジニアと言っても様々な職種※があります。
私は世間一般的に情報セキュリティ部やCSIRT/SOCのような自社の社内向けセキュリティ業務全般を担当してました。
※参考
セキュリティエンジニアに必要なスキル | IT業界職種研究 | IT転職 エージェント リーベル
昔セキュリティエンジニアをめざしたわけ
セキュリティエンジニアになりたいと思っていた一番大きな要素は、
技術的な興味と知識欲を満たしてくれるということでした。
自分が普段触っているPCやサーバがどのように動いているのか(CPUやメモリの動きや、プログラムがコンパイルされて動くまでの流れ、プロセスやネットワークのやり取りなど)、
知れば知るほど上手に使えるようになることに面白さを感じました。
今後様々なものがネットワークに繋がり便利になる一方で、セキュリティの問題が露呈し、 セキュリティエンジニアの需要が高まるだろうという市場の拡大にともなう人材不足(需要上昇)を視野に入れていました。
セキュリティエンジニアを辞めた理由
辞めた理由はいくつかありますが自分にとって大きいものは以下になります。
面白い(興味がある)部分と企業が求める部分とのギャップ
目指した理由に書いたとおり、技術的な面白さが好きでセキュリティエンジニアになったわけですが、 実際になってみると、認識が甘かったと痛感しました。 セキュリティエンジニアへの需要が増えることは予想通りだったのですが、 増えた需要は「企業内の情報セキュリティの事故が起きないようにする・起きても対応できる(最小化)ようにする」ことであり、 社内のセキュリティのIT技術力を上げることは「手段の一つかもしれないが目的ではない」というところです。
もっと言うと、日本の普通の企業はサービスや製品の脆弱性を見つけるエンジニアは不要であって、
会社全体のセキュリティを高めれるような、何かあっても対応できるような人材を欲しているというところです。
実際、社内セキュリティエンジニア(SIRT)をしているときに、転職サイトに自身のプロフィールを公開したところ、
誰もが知っている大企業や、ビットコイン系やら、昔働いていた会社やら、複数の会社からオファーやメッセージが届きました。
ただ、上に書いたように私がもともとやりたい方向に近かった脆弱性を見つけるようなことは、 今の日本では自社でやっているところは非常に少なく、基本的にはセキュリティベンダでないと業務としてやるのは難しいです。
心理的安全性がない
Googleの言うチーム間のコミュニケーションや雰囲気という意味ではなく、
いつセキュリティ事故が起きるかわからない(起きているけど気づいていない)というストレスに常に襲われていました。
そのため、事故の発覚が起きやすい連休明け前になると無意識にピリピリしていたように感じます。
事故も会社の規模や業態によって受ける被害は様々ですが、個人情報が流出したときの慰謝料や機会損失だけではなく、
工場などの古いPCが感染して生産ラインがストップすると日単位で数億円の損害が出るので、
事故発生時にはそれを自分がどうにかしないといけないという無意識が常時発生していました。
社員との対話が大変
セキュリティをやってみて一番以外だったのは、非常にコミュニケーション能力を求められるということです。
もちろんセキュリティ内の職種にもよりますが、社内セキュリティ担当は分業化されていることは少なく、複数の役柄を掛け持ちで少数人で回していることが多いのではないでしょうか。
そうなるとフォレンジックや侵入テストだけやれば良いなどはなく、社内ルールを決めたり、周知したり、どのように対策すれば良いか社員側と議論したり、
インシデントが起きたら正しく事象を把握するヒアリング能力などコミュニケーション能力がかなり求められる印象でした。
「今まで大丈夫だったし、なんの問題もないんだけど。」
「またセキュリティソフトが誤検知しているんですけど。」
こんな感じで仕事中は対話に時間と精神力が奪われていきます。
結局セキュリティは二の次
車の安全性を考えたときに、一番簡単な方法は"車を運転しないこと"ですが、
ただそれは不便で生活できません。
会社の運営も似ていてセキュリティを考えてあれこれ禁止にすると業務にならないので、なんとかするのも社内セキュリティエンジニアの仕事と思います。
ただPCを操作するのは社員なので、自分から安全装置を切ってスピード出して壁に突っ込んでも、その後処理や対策をこちらで考えないといけないのが辛いところです。
"運転しても事故にならないようになんとかしてよ。ただし運転するのは俺な。"
こんなイメージです。
正直無理ゲー
プロキシ入れようが、EDR入れようが、MSSを導入しようが、管理できない端末はたくさん出てきます。 業務や案件を盾に抜け道はいくらでもあります。 限りある予算と人員の中で可能な限りセキュリティを高めているのが現状だと思います。
社内のネットワークに勝手にRaspberryPiを繋がれたり、家のUSB,SDカードを悪気もなくPCに挿したり、
情シスに勝手に管理ソフトを入れられたくないからと故意にPCを登録しない&セキュリティソフトを入れない。
訳のわからないソフトをインストールしてセキュリティソフトがブロックするも誤検知でブロックされたんだけど!と怒る。
PCの管理者権限を渡さないなどシステム的に禁止にもできますが、
会社全体の生産性を下げ、こちらも運用負荷が発生し、なによりも誰からも感謝されないのが辛いところです。
けれど何か問題が起きたら社内セキュリティ担当者が対応しないといけない。 技術的な部分よりも人間力が非常に求められる職種だったと思います。
データサイエンティストになりました
そんなこんなで地方でセキュリティエンジニアを続けていくのはモチベーションとして難しいと判断し、 色々あってデータサイエンティストになりました。
なぜデータサイエンティストなのか/どうやってなったのかはここでは省きますが、 今は売上予測や、データの可視化などを行なっています。
社会人になってから今まで、運用という守りの仕事でしたが、
やっと0から1にするような仕事ができ満足度は上がりました。
最後に
私はもうセキュリティの仕事をしない決心をしていますが、 データサイエンティストの仕事をしていても、セキュリティエンジニア時代に身に着けたスキルが役立つことが多いです。 というかどんな仕事していてもセキュリティの知識は汎用性が高いので持っていて損はないと感じました。 ※現データサイエンティストの必要能力にセキュリティも含まれている
私の性格と社内情報セキュリティ担当という職種の相性が悪かっただけで、
上に書いた内容が全然平気、むしろやる気出るという人もいると思います。
社内情報セキュリティ担当の業務範囲は広くなりがちで大変なことが多いですが、その分比例して自身の技術スキルと社会的需要は爆上りなので、
自分のスキルや市場価値を上げたい!、社内セキュリティに興味がある!という人は是非やってみると良いと思います。
fluentdのプラグインを入れるときにエラーが出る

経緯
logz.ioの無料ELKサービスを試したかった。
ログを転送するためにfluentdのプラグインをAWSのサーバにインストールしようとしたときに、エラーが出たのでメモ。
環境
- AWSのインスタンス:Ubuntu16.04
以下の手順でfluentdをインストール logz.io
エラー内容
ubuntu:/opt/td-agent/usr/sbin$ sudo td-agent-gem install fluent-plugin-logzio
Fetching: net-http-persistent-2.9.4.gem (100%)
Successfully installed net-http-persistent-2.9.4
Fetching: serverengine-2.1.0.gem (100%)
Successfully installed serverengine-2.1.0
Fetching: strptime-0.2.3.gem (100%)
Building native extensions. This could take a while...
ERROR: Error installing fluent-plugin-logzio:
ERROR: Failed to build gem native extension.
current directory: /opt/td-agent/embedded/lib/ruby/gems/2.1.0/gems/strptime-0.2.3/ext/strptime
/opt/td-agent/embedded/bin/ruby -r ./siteconf20190311-4307-65kdm.rb extconf.rb
checking for rb_timespec_now()... *** extconf.rb failed ***
Could not create Makefile due to some reason, probably lack of necessary
libraries and/or headers. Check the mkmf.log file for more details. You may
need configuration options.
Provided configuration options:
--with-opt-dir
--with-opt-include
--without-opt-include=${opt-dir}/include
--with-opt-lib
--without-opt-lib=${opt-dir}/lib
--with-make-prog
--without-make-prog
--srcdir=.
--curdir
--ruby=/opt/td-agent/embedded/bin/ruby
/opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:467:in `try_do': The compiler failed to generate an executable file. (RuntimeError)
You have to install development tools first.
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:552:in `try_link0'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:567:in `try_link'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:747:in `try_func'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:1032:in `block in have_func'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:923:in `block in checking_for'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:351:in `block (2 levels) in postpone'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:321:in `open'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:351:in `block in postpone'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:321:in `open'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:347:in `postpone'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:922:in `checking_for'
from /opt/td-agent/embedded/lib/ruby/2.1.0/mkmf.rb:1031:in `have_func'
from extconf.rb:3:in `<main>'
To see why this extension failed to compile, please check the mkmf.log which can be found here:
/opt/td-agent/embedded/lib/ruby/gems/2.1.0/extensions/x86_64-linux/2.1.0/strptime-0.2.3/mkmf.log
extconf failed, exit code 1
Gem files will remain installed in /opt/td-agent/embedded/lib/ruby/gems/2.1.0/gems/strptime-0.2.3 for inspection.
Results logged to /opt/td-agent/embedded/lib/ruby/gems/2.1.0/extensions/x86_64-linux/2.1.0/strptime-0.2.3/gem_make.out
対応方法
$ sudo apt install gcc make
gccとmakeをインストールすることでエラーが出なくなった。
上記エラーにはgccやmakeなどの文言が出てこないので、分かりづらい。
WindowsServerのDHCPログをローテーションしたい
目的
WindowsServerのDHCPログは一週間分しか保持されない。
仕様により曜日ごとにログが生成され、一週間経つと上書きされてしまう。
そのため一日一回前日のログを別フォルダに日付名で保存させることでログを保全する。
使い方
ログの保全先フォルダを作成(以下スクリプトではC:\Windows\System32\dhcp\を指定)
WindowsServerのタスクスケジューラで一日一回実行してください。
コード
Powershellで実装。
# 機能 # WindowsServerのDHCPログを別フォルダに一日一回コピーする # # 目的 # WindowsServerのDHCPログは一週間分しか保持されない。 # 曜日ごとにログが生成され、一週間経つと上書きされてしまう。 # そのため一日一回前日のログを別フォルダに日付名で保存させることでログを保全する。 # # 使い方 # タスクスケジューラにこのバッチを一日一回セットする ## 参照先・保全先 $src_file_def = "C:\Windows\System32\dhcp\" # DHCPのデフォルトログの保存先 $dst_file_def = "C:\Windows\System32\dhcp\log\" # コピー先(保全先)のディレクトリ ## 前日の日付取得 $date = (Get-Date).AddDays(-1).ToString("yyyyMMdd"); ## コピー先(保全先)のファイル名を生成 $dst_file = $dst_file_def + "$date" + ".log" ## コピー元のファイル名 $youbi = (Get-Date).AddDays(-1).DayOfWeek # 前日の曜日を取得 $youbi_3 = "$youbi".Substring(0,3) # 前日の曜日から頭3文字を抜き出す(Sunday→Sun) $src_file = $filename_def + "DhcpSrvLog-" + $youbi_3 +".log" #echo $src_file #echo $dst_file ## コピーを作成 Copy-Item -Path $src_file -Destination $dst_file -Force
その他
急遽必要になったのでさっと作ったが、結局自分では使わなかったので、これが本当に使えるのか未検証です。
多分DNSログにも使えると思う。
WindowsのDHCPログで調べると「仕様がクソ」みたいな記事が出てくるけど、確かにそう思う。なんでこんな仕様なんだろうか。